前面已經介紹過了一個非常有趣的 P0 事件,這次則要介紹另一個同樣非常值得分享的事件。而且該事件的根本成因一直到現在都沒有完全解決,每隔一段時間就有可能再度發生,成為了我們服務的某個穩定性上的隱憂。
整起事件的開頭是從一個 Pingdom DOWN 的警報開始的。避免讀者忘記,在介紹基本監控系統的文章中有提到過, Pingdom DOWN 代表某個特定的服務已經無法存取,因此是比較嚴重的警報。與上一篇中提到的全站警報不同,這次只有發生在某專案的其中一個小服務而已,但因為是無法存取的狀況,因此也還是算相對嚴重的狀況。
由於該服務主要建立在 EC2 的解決方案上,並用 OpsWorks 進行部署,因此筆者馬上點進了兩者的主控台上查看,並在 OpsWorks 的主控台上觀察到, EC2 雖然能夠成功註冊到 OpsWorks ,但接下來卻無法正常進行後續的步驟,也就是 Recipe 中有關各種程式的安裝步驟。
既然能夠成功註冊 OpsWorks ,就代表這裡的問題並非之前在日常維運系列文中有提到的,有機率註冊 OpsWorks 失敗的情況。
在這種情況下,一般我們能做的就會是先查看各種能夠找到的日誌,而最先能想到的,當然就是 OpsWorks 的日誌。透過 error 之類的關鍵字來搜尋,最後從該日誌中可以找到以下的訊息:
## Populating apt-get cache...
+ apt-get update
Reading package lists...
Error executing command, exiting
從該訊息中我們可以發現, Ubuntu 的套件管理工具 apt-get 似乎出現了一些問題,導致所有我們需要的套件都無法安裝,進一步導致相關的機制無法運作。然而,筆者在當下完全無法找出來該問題的成因,在查了十幾鐘後都還沒有任何進展。
非常幸運地是,另外一位資深前輩剛好還沒有睡(?),出面協助之後翻出了下面這一串日誌訊息:
[0mE: Failed to fetch http://ap-northeast-1.ec2.archive.ubuntu.com/ubuntu/pool/universe/libu/libuv1/libuv1_1.8.0-1_amd64.deb 503 Service Unavailable [IP: 18.183.160.212 80]
而這個問題說穿了其實非常單純,因為 EC2 在啟動的時候,會需要 Ubuntu 伺服器拿取與作業系統相關的個種資訊。但因為 Ubuntu 伺服器的服務自己出現問題,導致我們一開始就無法完整地安裝作業系統。這其實是一個 Ubuntu 的全球災情,因此也在許多地方出現同樣問題的討論。比如這篇:「https://github.com/orgs/community/discussions/44171」。如下圖:
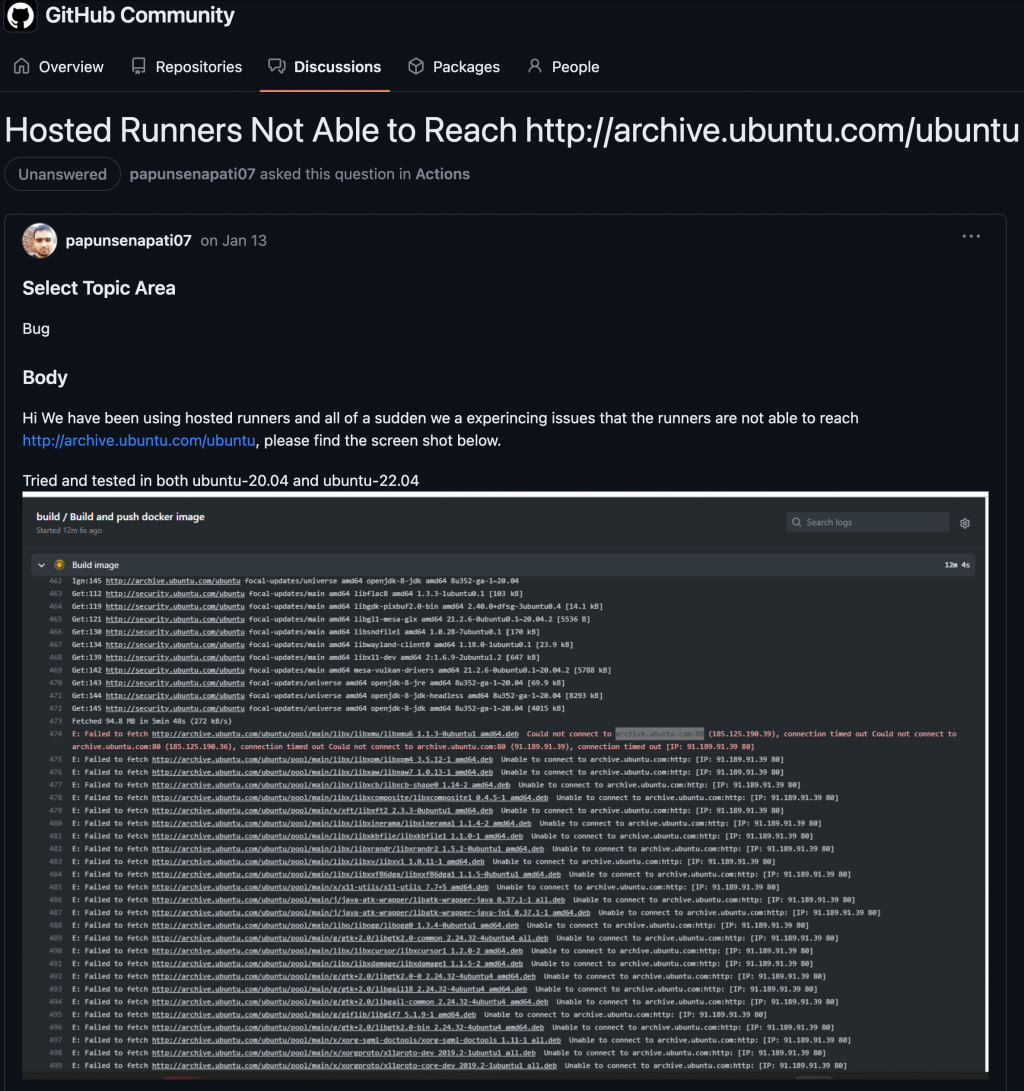
然而,因為 Ubuntu 伺服器不在我們的管理範圍中,因此雖然理解了事件的成因,我們卻毫無辦法,只能等待 Ubuntu 伺服器自行修復才解決這次的事件。
在這個事件中,服務要受到影響,必須符合以下三個條件:
因為我們的主要服務全部都有搭配自動擴展的機制,因此一般來說線上的伺服器不會只有一台。即使出現開關機的狀況,通常線上也還會有其它本來就開好的機器來支撐服務的可用性,雖然伺服器數量不夠可能會導致回應變慢,但還不致於到無法存取的狀況。
前述會發生 Pingdom DOWN 的狀況裡,其實只是剛好有其中一個服務,好巧不巧,剛好舊伺服器正在全部被汰換掉而已。事後發現,其它服務也有一模一樣的無法開機狀況,只是尚有舊的伺服器支撐而沒有出現無法存取的狀況。
然而,該狀況接下來卻逐漸演變成一個嚴重的不定時炸彈,也就是在任何時間點都有可能導致嚴重 P0 事件。因為我們其中一個服務被發現有 memory leak 的狀況,如下圖:
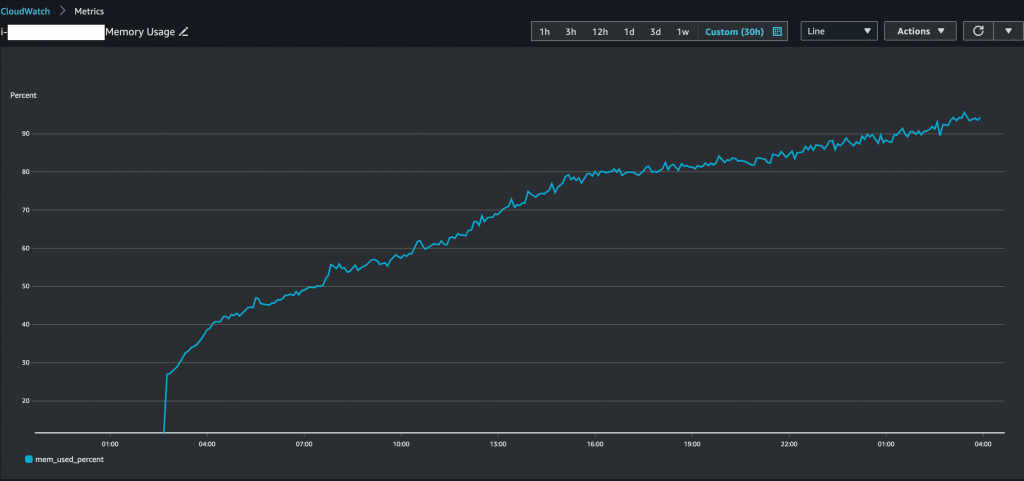
每台使用該服務的伺服器,大約會在在啟動後的30小時內出現記憶體使用量爆表的狀況。因為在該狀況下無法給出回應的關係,伺服器會被判定為是不健康的機器而被關掉(terminated),並透過自動擴展機制來自動開啟(launch)一台新的伺服器取代之。
相信各位讀者應該可以看出這邊的問題了。這個每隔一段時間都必須要使用新機器來取代舊機器的狀況,只要很不巧地撞上了 Ubuntu 伺服器無法存取的問題,就有可能會導致新伺服器無法開啟。雖然在無法開啟的當下,仍然會有其它舊伺服器繼續運作,但也因為 Ubuntu 伺服器的故障可能會維持一段時間,只要這個時候其它舊伺服器也因為記憶體爆表而被迫關機的話,就會進入整個服務無法存取的狀況。
而實際上,這也已經導致另一次重大 P0 事件了。也因為這件事情的急迫性,才促使我們的開發工程師投入了更多的資源來解決該 memory leak 的問題。說實話,也是非常感謝他們當時的協助,才能暫時解決這個不定時炸彈,不然在那之前,我們是先透過加大伺服器記憶體或是增加伺服器同時在線數量,來或多或少降低發生事件的可能性而已。
雖然前述的 memory leak 最後有解決,但本文的主要問題卻尚待研究。對於 Ubuntu ,我們基本上是無能為力的,因此我們就必須從其它角度切入才行。
首先,針對事件當下的緊急處置,我們所要做的就是避免陷入完全沒有機器的窘境,因此當 Ubuntu 伺服器已經出現異常的時候,我們要避免已經在線上運作的伺服器被關掉的狀況。這個做法其實相當簡單,因為 AWS 本身在自動擴展的機制中就有給予相關的設定,該設定被稱做「scale-in protection」,也就是避免 EC2 在 scale in 的過程中被關機。
至於我們要怎麼知道 Ubuntu 伺服器出現異常呢?雖然我們直接監控 Ubuntu 伺服器的 endpoint 也是一種方法,但我們在這裡是透過設定 EC2 啟動失敗的警報來知道這件事情的。因為 EC2 啟動失敗本身除了 Ubuntu 問題外,可能還有其它因素,因此是一個值得且本來就有被設定要監控的項目。在這件事情上我們就不需要再額外花費心力監控 Ubuntu 伺服器的狀況。
其次,針對比較長遠的處置,我們提出了 AWS Golden Image 的解決方案。這個方案簡而言之,是透過預先裝好大部分 EC2 啟動時所需要的資訊在映像檔(AMI)中,來避開伺服器在啟動時還需要向 Ubuntu 伺服器索取資訊的過程。
不過,最後我們因為其它原因而直接改採用容器化方案,因為容器化本身直接避免了這個問題,因此這個問題在之後就真正地完全解決了。至於我們容器化的原因,筆者也會在之後的章節再說明。
雖然這主要會是產品經理的職責,但在嚴重 P0 事件處理完之後,要如何究責也會是另一個學問,特別是我們有簽訂 SLA 合約的前提之下。
以上一個 P0 事件而言,因為是客戶沒有按照合約行動,因此責任完全在他們那方。然而在這個事件中,究竟責任是否歸屬於我們就會變得相當微妙。雖然技術上這應該算是 Ubuntu 伺服器的問題,因此這應該不是我們的責任,但從客戶的角度來說,也可能會理解成是我們技術問題導致的服務中斷,因此而向我們究責。
雖然做為 SRE ,我們只要把技術細節或相關資訊提供給產品經理即可,但如同在日常維運系列文章中的棒球賽事件一樣,筆者認為,一個稱職的 SRE 應該要能為產品經理多做這一層的思考,並進一步提供跟據這個思考而獲得的有用資訊。在此也把這個想法分享給讀者們。
下一篇,將會是另一個和成因與這次事件類似的嚴重 P0 事件。


 iThome鐵人賽
iThome鐵人賽